- 依依网-微信公众平台文章推荐
选自 arXiv [转载出处:www.11jj.com]
作者:Nouamane Laanait、Joshua Romero等 [好文分享:www.11jj.com]
机械之心编译
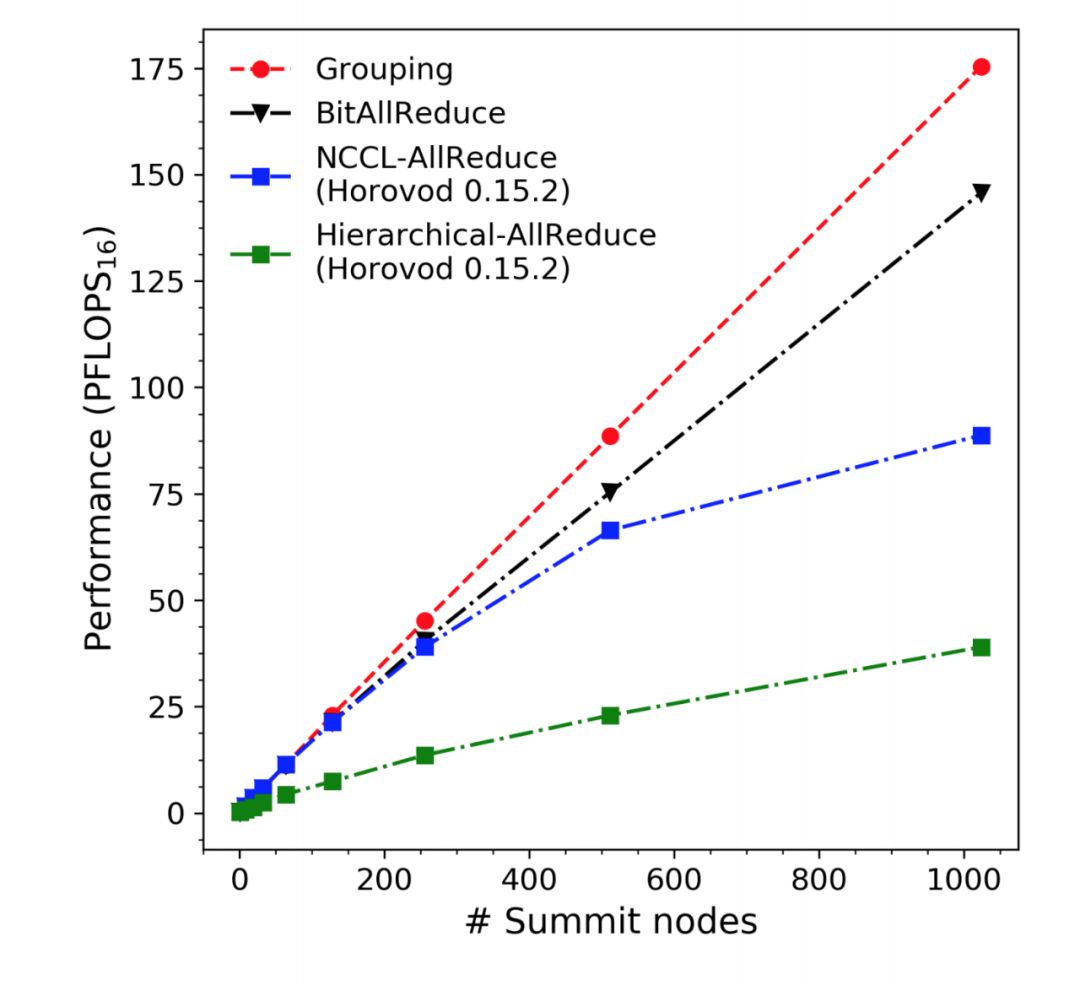
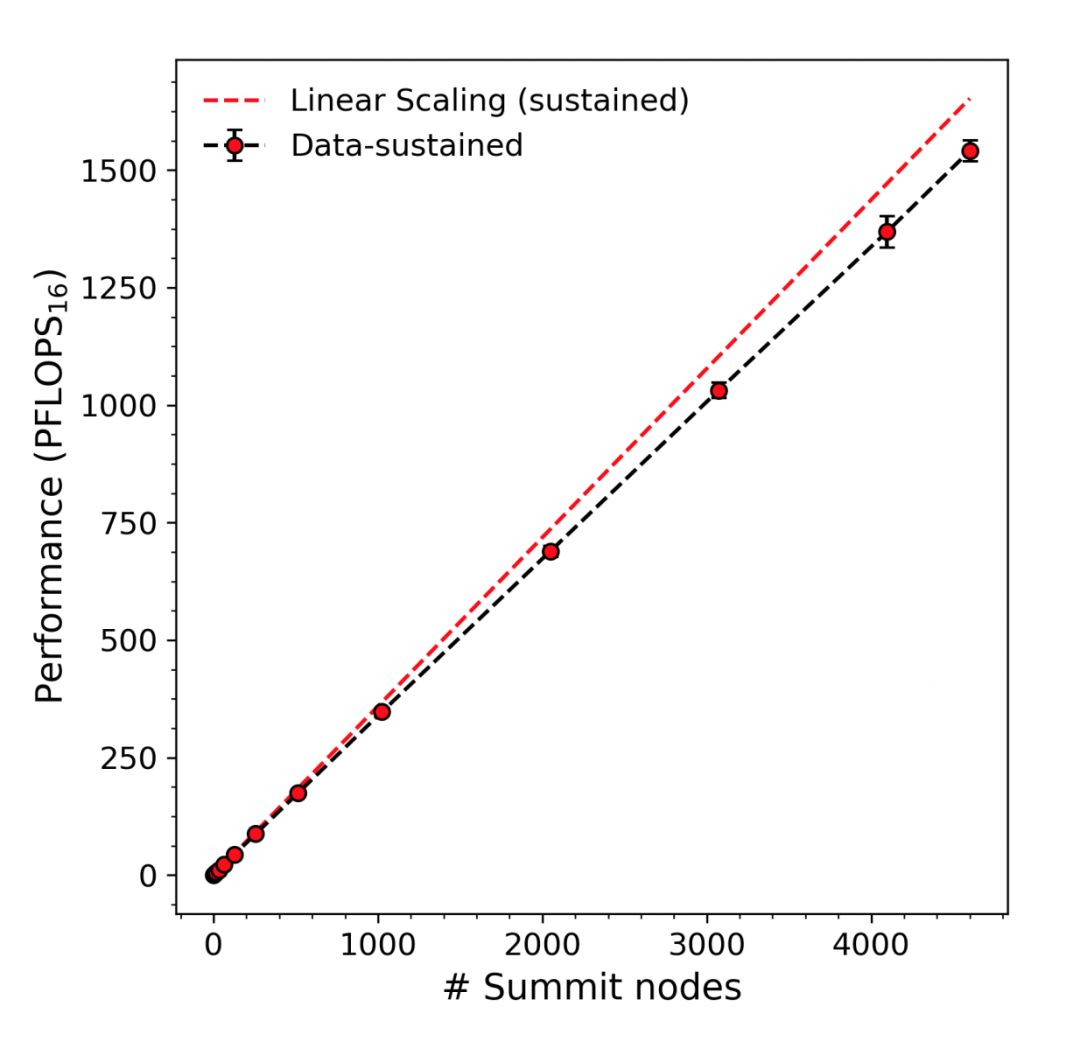
分布式角力切实需要在多少 GPU 上演习,但你见过在排名第一的超算上演习深度模型,在 2.76 万块 V100 GPU 演习模型的体式吗?首要的是,经由新的通信策略,这么多 GPU 还能实现近线性的加速比,橡树岭国度实验室和英伟达等机构的这项研究真的 Amazing。
什么是分布式演习
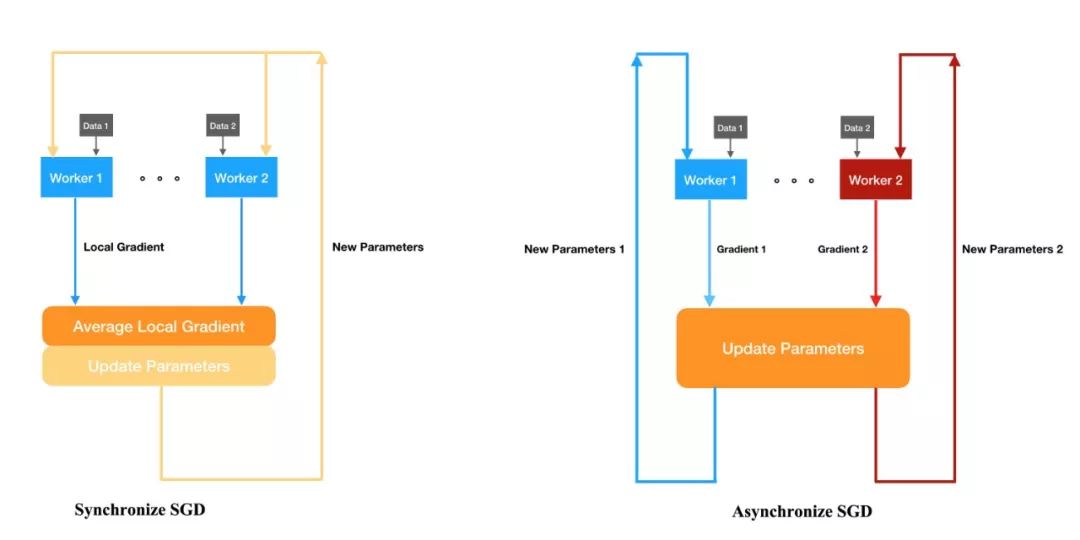
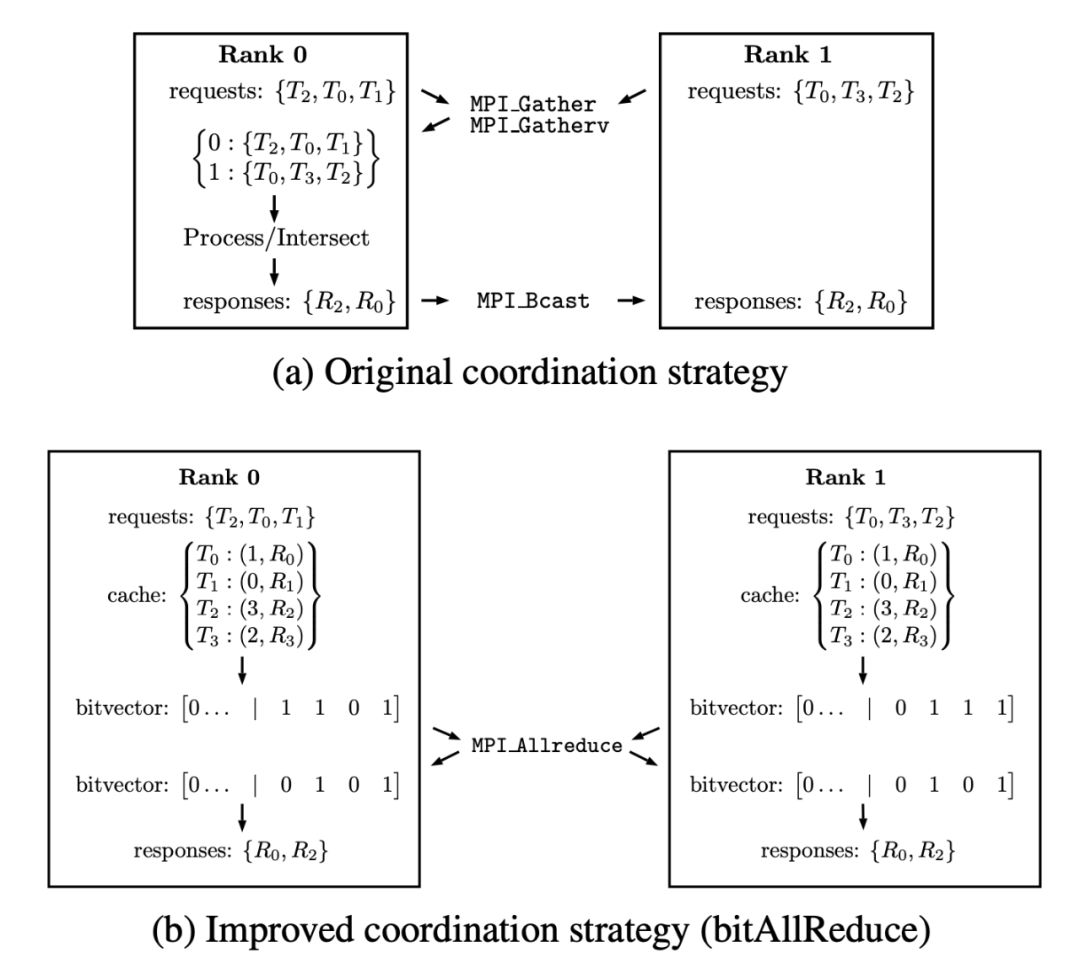
数据并行的问题在哪?
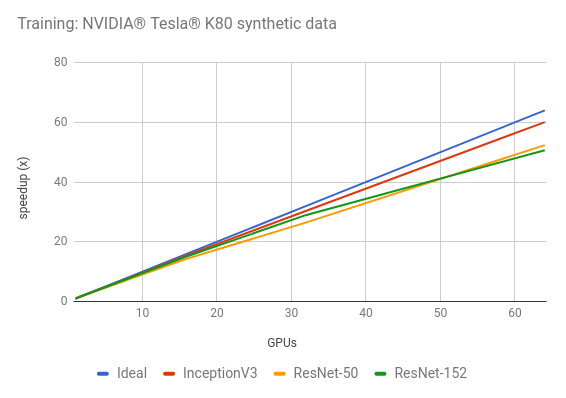
用超算测测数据并行

www.jiqizhixin.com/sota
PC 接见,体验更佳

比来,呼市的高师长因为车出了故障就送到4S店修理,可是这车没修好不说还修出了一肚子气。 2022年1月,高师长在呼市中庆林达林肯中心花
大家好,小乐今天来为大家解答怎么跑步跑得快不累以下问题,跑步怎么跑得快很多人还不知道,现在让我们一起来看看吧!1、想要跑步跑得快,首先
大家好,小丽今天来为大家解答交叉关系举例以下问题,交叉关系举例三个词很多人还不知道,现在让我们一起来看看吧!1、比如,陕西人:专家,
大家好,小乐今天来为大家解答空待以下问题,空待君不回很多人还不知道,现在让我们一起来看看吧!1、《空待》是一首由王朝和天依合作的VOC
研途漫漫,他们披星带月荆棘丛丛,他们甘之如饴保研路上他们用无悔的对峙践行着心中的妄想收获了满径花香本期让我们一路走近保研学子机械设
比来,江南、华南强对流天色频发,3 月 31 日凌晨,江西省南昌市突发强对流天色,最强时段是 3:00 前后,南昌市、南昌县观测到了 9 级大风,进贤
大家好,小伟今天来为大家解答怎么关闭开机自动启动的软件以下问题,怎么关闭开机自动启动软件win7很多人还不知道,现在让我们一起来看看吧!
大家好,小娟今天来为大家解答世界美院排名以下问题,世界美院排名前100很多人还不知道,现在让我们一起来看看吧!1、2023年米兰布雷拉美术学院
Copyright 2024.依依自媒体,让大家了解更多图文资讯!