- 依依网-微信公众平台文章推荐

[好文分享:www.11jj.com]
【CSDN 编者按】四个参数,我就能拟合出一个大象出来,用五个参数我就能让他的鼻子摆动
[本文来自:www.11jj.com]
模型原理
关于 MOE
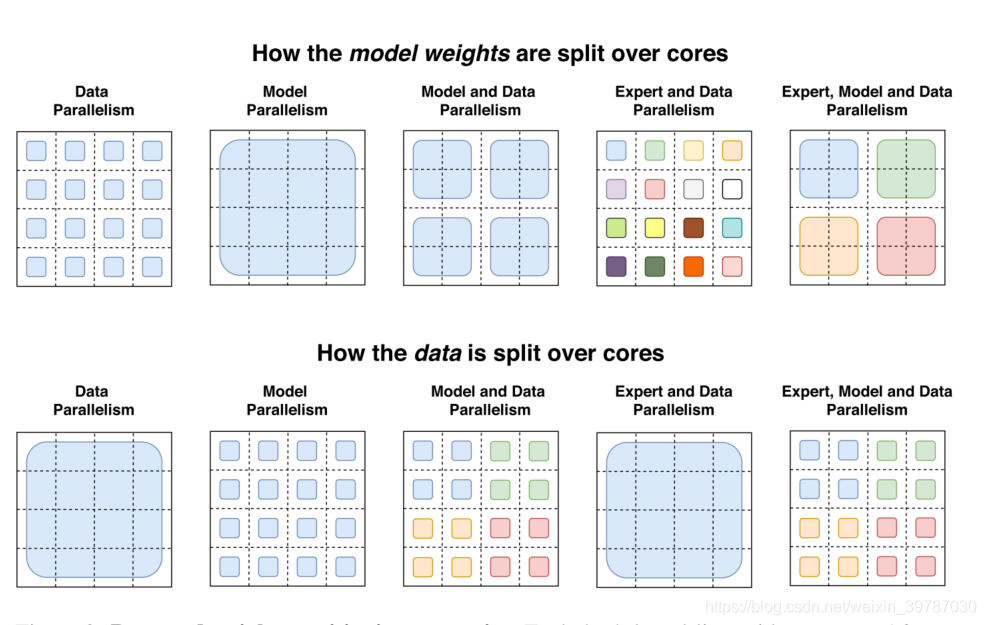
权重分配与近水楼台
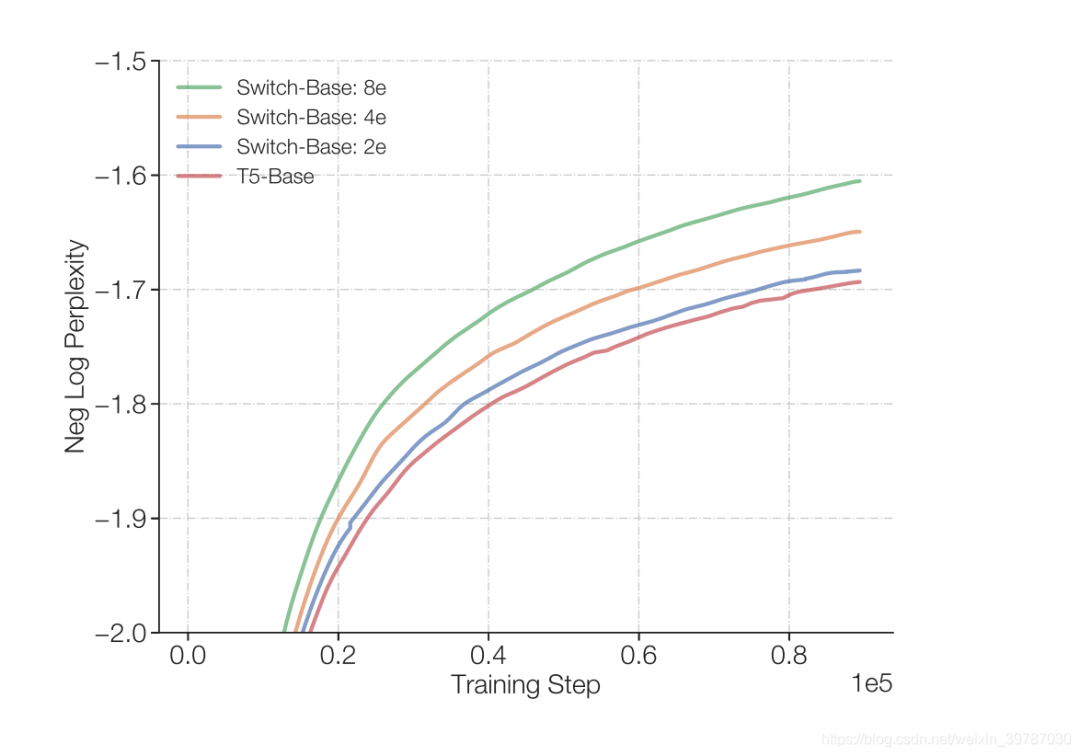
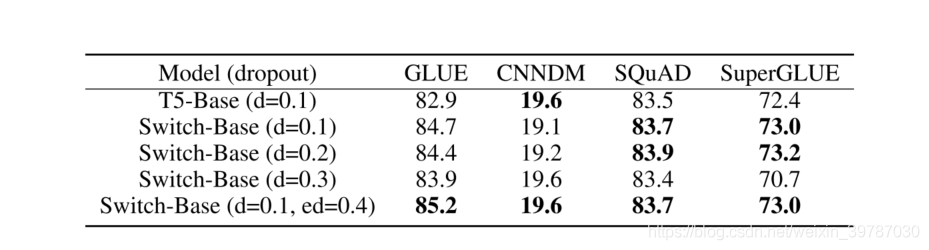
跑个分~
当场答疑
纯粹的参数技术会让 Switch Transformer 更好吗?
是的,看怎么设计!参数和总的 FLOPs 是独立衡量神经语言模型的标准。大型模型已经被证实具有良好的表现,不过基于相同计算资源的情况下,我们的模型具有更加简洁、有效且快速的特点。
我没有超算——模型对我来说依然有用吗?
虽然这项工作集中在大型模型上,我们发现只要有两个专家模型就能实现,模型需要的最低限制在附录当中有讲,所以这项技术在小规模环境当中也非常有用。
在速度-精度曲线上,稀疏模型相比稠密模型有优势吗?
当然,在各种不同规模的模型当中,稀疏模型的速度和每一步的表现均优于稠密模型。
我无法部署一个万亿参数的模型-我们可以缩小这些模型吗?
这个我们无法完全保证,但是通过 10 倍或者 100 倍蒸馏,可以使模型变成稠密模型,同时实现专家模型 30%的增益效果。
为什么使用 Switch Transformer 而不是模型并行密集模型?
从时间角度看,稀疏模型效果要优越很多,不过这里并不是非黑即白,我们可以在 Switch Transformer 使用模型并行,增加每个 token 的 FLOPs,但是这可能导致并行变慢。
为什么稀疏模型尚未广泛使用?
扩展密集模型的巨大成功减弱了人们使用稀疏模型的动力。此外,稀疏模型还面临一些问题,例如模型复杂性、训练难度和通信成本。不过,这些问题在 Switch Transformer 上也已经得到了有效的缓解。
参考资料:https://arxiv.org/pdf/2101.03961.pdf 项目代码地址:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py
end
更多精彩推荐 ☞突发!Intel CEO 换帅,VMware CEO 将走马上任
☞微信封杀 QQ 音乐、拼多多等 App 外链;蠕虫病毒在国内肆虐;Dropbox 宣布裁员 |极客头条
☞除了 Docker,我们还有哪些选择?
点分享 点收藏 点点赞 点在看

大家好,小豪今天来为大家解答伊嘉儿数学教学质量如何以下问题,伊嘉儿数学长期班教材很多人还不知道,现在让我们一起来看看吧!1、伊嘉儿数
大家好,小娟今天来为大家解答涤纶和尼龙的区别是什么材料以下问题,涤纶面料与尼龙面料哪个好很多人还不知道,现在让我们一起来看看吧!1、
大家好,小美今天来为大家解答动脉粥样硬化的原因及解决办法以下问题,动脉粥样硬化是什么很多人还不知道,现在让我们一起来看看吧!1、一般
大家好,小豪今天来为大家解答五岳名山分别在哪里以下问题,五岳名山的名称及所在省份很多人还不知道,现在让我们一起来看看吧!1、中国五大
大家好,小伟今天来为大家解答企业核名流程以下问题,企业核名成功去什么地方查询很多人还不知道,现在让我们一起来看看吧!1、工商局名称核
大家好,小伟今天来为大家解答杨梅里的虫子能吃吗以下问题,杨梅里的虫子可以吃嘛很多人还不知道,现在让我们一起来看看吧!1、杨梅里的白色
大家好,小豪今天来为大家解答我现在的具体位置在哪以下问题,我现在的具体位置叫什么很多人还不知道,现在让我们一起来看看吧!1、首先打开
大家好,小丽今天来为大家解答傅声死的现场照片以下问题,傅声死亡过程很多人还不知道,现在让我们一起来看看吧!1、1983年7月6日晚间10点半,
Copyright 2024.依依自媒体,让大家了解更多图文资讯!