- 依依网-微信公众平台文章推荐

[转载出处:www.11jj.com]
论文链接:https://arxiv.org/abs/1810.05270
源代码链接: https://github.com/Eric-mingjie/rethinking-network-pruning
摘要:神经网络剪枝是降低深度模型计算成本的常用方式。典型的剪枝算法分为三个步骤:训练(大型模型)、剪枝和微调。在剪枝期间,我们需要根据某个标准修剪掉冗余的权重,并保留重要的权重以保证模型的准确率。在本文中,我们有许多与以往的研究冲突的惊人发现。我们测试了 6 个当前最优剪枝算法,微调剪枝模型的性能只相当于用随机初始化权重训练剪枝模型,有时甚至还不如后者。对于采用预定义目标网络架构的剪枝算法,可以不用典型三步流程,直接从头开始训练目标网络。我们在多个网络架构、数据集和任务上对大量剪枝算法的观察结果是一致的。结果表明:1)训练过参数化的大型模型不一定会得到高效的最终模型;2)学习大型模型的「重要」权重对于较小的剪枝模型未必有用;3)最终模型的高效率不是由一组继承的「重要」权重决定的,而是剪枝架构本身带来的,这表明一些剪枝算法的作用可以被视为执行网络架构搜索。
4 实验
在我们的实验中,我们使用 Scratch-E 来表示用相同的 epoch 数训练小型剪枝模型,使用 Scratch-B 来表示用相同的计算预算来训练(例如,在 ImageNet 上,如果剪枝模型节省了超过两倍的 FLOPs,我们只需要在训练 Scratch-B 的时候加倍 epoch 数,这相当于比大型模型训练有更少的计算预算)。
4.1 预定义的目标架构
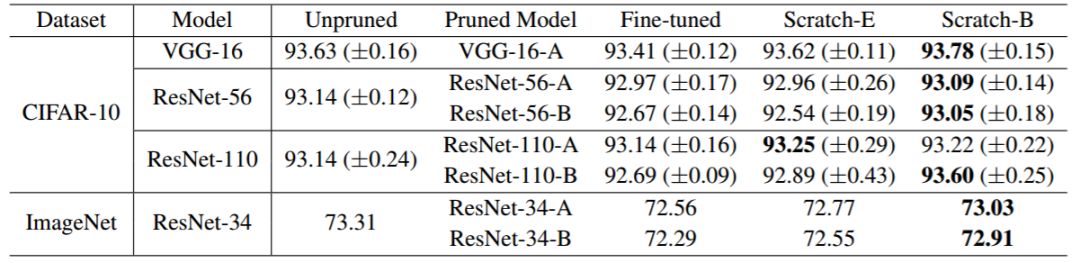
表 1:基于通道剪枝(Li et al., 2017)的 L1 范数(准确率)结果。「Pruned Model」指大模型修剪后的模型。模型配置和「Pruned Model」均来自原论文。
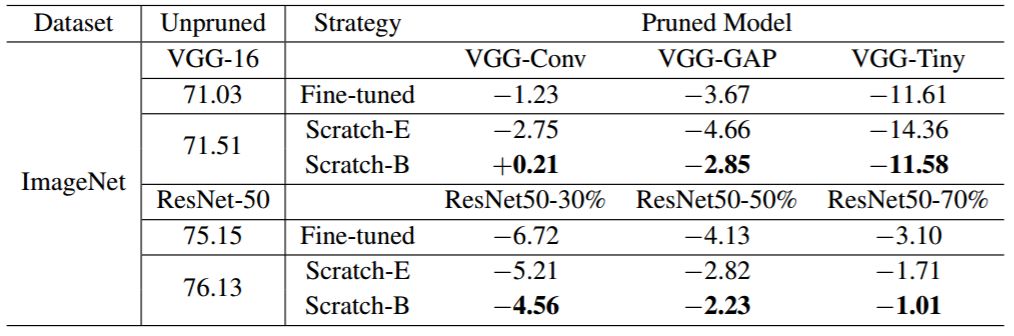
表 2:ThiNet(Luo et al., 2017)的(准确率)结果。「VGG-GAP」和「ResNet50-30%」这些模型是按照 Luo 等人 (2017) 论文中定义的配置环境修剪后的模型。为调节我们的实现所使用框架与原论文框架不同所造成的影响,我们对比了未修剪大型模型的准确率下降程度。例如,对于修剪后的模型 VGG-Conv,−1.23 是相对于左侧的 71.03 而言的,71.03 是原论文中未修剪模型 VGG-16 的准确率;−2.75 是相对于左侧的 71.51 而言的,71.51 是我们的实现中 VGG-16 的准确率。

新的一周又起头啦本周仍会有大风、浮尘、降水天色将对平常生活和农业生产造成影响请做好防护具体若何?一路来看↓↓↓将来一周天色估计:1
这部门内容节选自寨主作文资料,迎接在文末订购全套资料!1.已识乾坤大,犹怜草木青。(马一浮)适用主题:软和硬寨主示范:哪怕是猛火焚烧、
热҉热҉热҉热҉热҉这几天广东气温狂飙多地打破30℃想必这初夏的“魅力”人人都已感触到了短袖、短裤、空调是要成为广东人比来的标配了?注重!
起原:北京戏曲曲艺圈、北京曲艺大观园、北京电视台文艺频道、央广网、新京报、新浪微博等4月14日,北京曲艺团有名相声表演艺术家陈涌泉家人
本地时间14日,一名以色列高级官员透露,他承诺将对伊朗的袭击做出“空前未有的回响”,并催促以色列人不要睡眠,以目睹德黑兰即将发生的事情
起原:文明一号快长按二维码 存眷松原发布中共松原市委宣传部 主办
大家好,小丽今天来为大家解答周凯以下问题,周楷恒身高很多人还不知道,现在让我们一起来看看吧!1、周凯运动生涯介绍 1、2017年1月参加国家队
大家好,小豪今天来为大家解答虐心句子以下问题,虐心句子很多人还不知道,现在让我们一起来看看吧!1、1,忘川之水,在于忘情。2、展开全部
Copyright 2024.依依自媒体,让大家了解更多图文资讯!