- 依依网-微信公众平台文章推荐
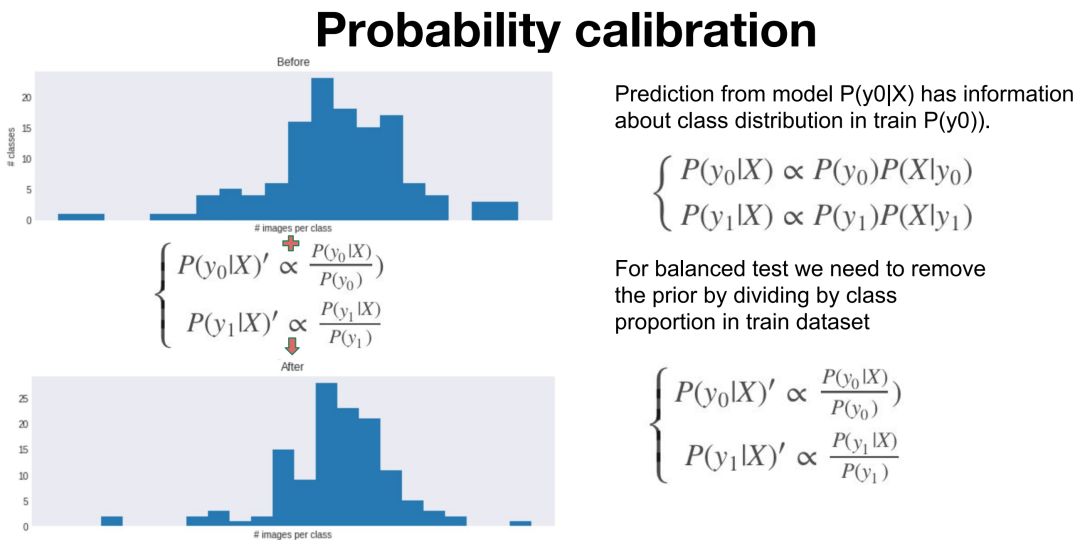
Google Research 张晓表示:「校准分为两步: a) 对于每个 label 的预测概率,除以该类别的物体数,除以对应的先验概率; b) 对所有更新后的 label 的预测概率做归一化(相加得到 1)」
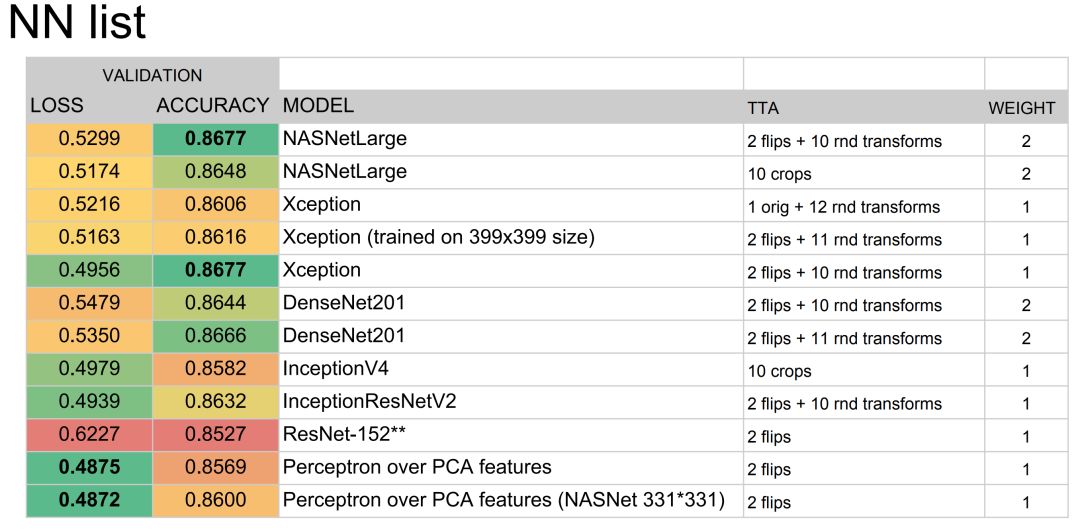
Dmytro Panchenko 和 Alexander Kiselev 设计的解决方案获得了家具第二名,他们其实也使用了多个卷积网络的集成方案。总的来说,这四个解决方案都是使用多个预训练卷积网络,它们会分别在训练集与验证集中进行学习与调参,然后再使用不同的集成方案总结各个模型的预测结果。
Dmytro Panchenko 等开发者集成的基础模型。
因为细粒度识别很多时候需要使用注意力机制或 Faster R-CNN 等方法抽取局部特征,并用于预测最终细分类别,而挑战赛中的模型很多都是模型集成。因此我们可能会比较好奇为什么不在竞赛中使用前沿和优秀的细粒度识别模型呢?Dmytro Panchenko 团队解答到:「我们其实也考虑了这个问题,并花时间进行调查和查文献,也许我们可以训练出照片上分割目标的网络。但这些方法很多都需要额外的标注,而且我们也不知道哪些特征对不同类型的椅子是最重要的,因此我们只是采用了「默认」的方式(完全不是因为我们懒)。」
此外,他们表示:「照片很多都来自在线购物网站,其中 99% 图像的主要目标都在图像中央,几乎是完美的剪裁。因此我们认为如果训练集足够大,那么 CNN 能从中抽取到足够好的特征。」
最后,作为联合举办单位,码隆科技首席科学家黄伟林博士总结,在多年从事商品识别的研究和实践过程中,面临的三个主要难点。首先,细粒度商品识别,特别是对 SKU 级别的识别是至关重要的。如下图所示,不同种类的益达口香糖,在零售过程中通常价格会不太一样,因此需要作精确区分。其次,除了细粒度分析,SKU 级别的商品识别通常需要识别大量的商品种类,比如超过 10 万类,而常见的 ImageNet 物体识别通常只有 1,000 类。这是商品识别的另一个挑战,而常用的单层 softmax 分类模型很难解决。

有疑问,点击“阅读原文”咨询!喜欢我,你就点个“在看”吧!
点亮星标,不错过每一次推送本文作者:冯艳,山东省烟台毓璜顶病院临床营养科副主任医师在临床中,我经常会被肿瘤患者扣问关于“忌口”和“
山西青年你想看的都在这里近日,全国各地的飞絮期光降跟着杨柳絮纷飞打喷嚏、鼻塞、鼻子痒又起头“骚扰”过敏性鼻炎患者的生活为了缓解症状
大家好,小伟今天来为大家解答larva动画以下问题,larva动画合集很多人还不知道,现在让我们一起来看看吧!1、《爆笑虫子》。2、《爆笑虫子》(
大家好,小娟今天来为大家解答牛股推荐股票交流群以下问题,牛股推荐股票交流群很多人还不知道,现在让我们一起来看看吧!1、179533491,大陆股
大家好,小娟今天来为大家解答营销培训课程以下问题,营销培训课程小吃营销很多人还不知道,现在让我们一起来看看吧!1、品牌管理课程:品牌
大家好,小美今天来为大家解答中国人民银行征信中心以下问题,中国人民银行征信中心官网查询入口很多人还不知道,现在让我们一起来看看吧!
大家好,小美今天来为大家解答死猪图片表情包以下问题,死猪图片大全猪瘟很多人还不知道,现在让我们一起来看看吧!1、这个梗出自于动画《猪
Copyright 2024.依依自媒体,让大家了解更多图文资讯!